DiscoGen is a procedural generator for algorithm discovery tasks in machine learning, capable of generating over 400 million unique tasks across 10+ domains including Reinforcement Learning and Bayesian Optimization. It introduces DiscoBench, a standardized benchmark for evaluating Algorithm Discovery Agents (ADAs) using a principled meta-train/meta-test separation.
TL;DR
Researchers have just released DiscoGen, a massive engine that procedurally generates millions of unique "Algorithm Discovery" tasks. Unlike previous benchmarks that are easily "cheated" by LLM memory, DiscoGen forces AI agents to actually invent machine learning components (like loss functions or optimizers) and validates them on totally unseen datasets.
The Problem: When Benchmarks become Memory Tests
We are entering the era of "AI Scientists"—agents designed to write code, run experiments, and discover new ML theories. However, current benchmarks like MLE-Bench have a fatal flaw: Data Contamination. Because they use fixed Kaggle-style problems, a model like GPT-4 might have already seen the solution in its training data. Furthermore, these benchmarks don't separate the "discovery phase" from the "testing phase," leading to agents that overfit to a single dataset rather than finding a robust algorithm.
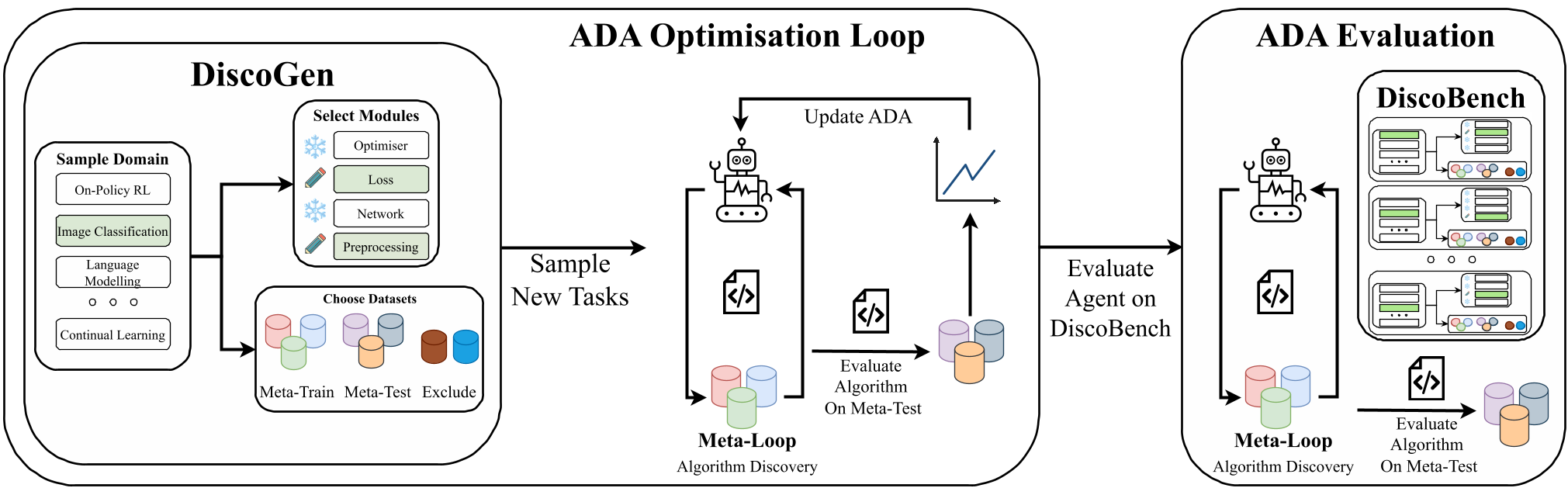
DiscoGen: A Combinatorial Explosion of Research
The authors propose a "Meta-Meta-Loop" architecture. Instead of one task, DiscoGen uses 7 axes of configuration to create a massive variety of research problems:
- Task Domain: (e.g., On-Policy RL, CV, Language Modeling).
- Editable Modules: The agent is given "blanks" (e.g.,
compute_loss()) to fill in. - Meta-Train/Test Split: The agent sees Task A to develop the code, but the code is evaluated on Task B.
The math is simple but powerful: with $m$ modules and $d$ datasets, the number of tasks grows exponentially. In the On-Policy RL domain alone, DiscoGen supports over 426 million distinct settings.
Methodology: The Inner, Meta, and Meta-Meta Loops
To understand how DiscoGen works, we have to look at the three nested loops:
- Inner-Loop: A standard ML training run (e.g., training a ResNet on CIFAR).
- Meta-Loop: The ADA (Algorithm Discovery Agent) iterates on the code itself based on Inner-Loop feedback.
- ADA Optimisation Loop: This is where DiscoGen shines—researchers can optimize the agent itself (its prompts or weights) across hundreds of different Meta-Loops.
Key Findings: Can LLMs Actually "Invent"?
The results from DiscoBench (the curated subset for evaluation) are a wake-up call for the industry:
- Complexity Barrier: Success rates for current SOTA models (DeepSeek-v3.2, etc.) plummet as the number of editable modules increases. If an agent has to write the network and the loss and the optimizer from scratch, it usually fails.
- Prompt Evolution: The authors proved that by "tuning" the ADA's prompt across 30 different DiscoGen tasks, they could create a "Generalist Researcher" prompt that significantly outperformed prompts tuned on a single task.
| Model | Success Rate (Single Module) | Success Rate (All Modules) | | :--- | :--- | :--- | | DeepSeek-v3.2 | 80.0% | 25.7% | | GPT-OSS 120B | 68.2% | 11.4% |

Deep Insight: Beyond Code Generation
The most striking takeaway is that "winning" in meta-training often leads to "losing" in meta-testing. Agents often found "hacks" (like hardcoding shapes) that worked for one dataset but crashed on the next. This highlights why Procedural Generation is the only way forward: it turns the "AI Scientist" problem from a coding task into a generalization task.
Conclusion & Future Look
DiscoGen provides the "XLand" or "NetHack" equivalent for ML research. By open-sourcing a generator that creates 493 million tasks, the authors have provided the playground necessary for RL-based self-improvement in AI scientists. The next step? Training "Algorithm World Models" that can predict the performance of a new loss function before even running a single epoch.
Takeaway for Practitioners
If you are building agentic workflows for R&D, stop testing on single datasets. Use the DiscoGen philosophy: evaluate the transferability of the generated logic to ensure your agent isn't just a very expensive "copy-paste" tool.