The paper introduces ExpRAG, a framework that augments LLM agents with episodic experience retrieval and proposes ExpRAG-LoRA for fine-tuning. It achieves SFT-level performance on in-distribution tasks while significantly outperforming standard fine-tuning on unseen tasks (e.g., ALFWorld success +20-50% on OOD tasks).
TL;DR
Supervised Fine-Tuning (SFT) makes agents great at what they've seen, but brittle at what they haven't. This paper from NAVER LABS Europe introduces ExpRAG-LoRA, a method that integrates episodic memory retrieval directly into the training process. The result? Agents that don't just memorize actions but learn to use retrieved examples to solve brand-new tasks, achieving nearly 3x higher success rates on unseen tasks compared to standard SFT.
The Problem: The Generalization Wall
Current LLM agent research usually falls into two camps:
- Fine-tuning (SFT/LoRA): Excellent performance on training tasks, but performance "collapses" when the agent hits a new environment or task type (e.g., trained to clean, asked to heat).
- Training-free RAG: Using frozen models with retrieved context. This generalizes better but often fails to reach the raw performance peaks of fine-tuned models.
The authors identify a critical missing link: Learning to use the memory. If an agent is never trained to look at its "past experience" block during fine-tuning, it won't know how to leverage it effectively when things get tough at inference time.
Methodology: ExpRAG and ExpRAG-LoRA
The team systematically broke down the "Experience Retrieval-Augmented Generation" (ExpRAG) pipeline into three phases:
1. The Experience Bank
Instead of abstract reflections or summaries, the authors store full raw trajectories (multi-turn chats) in a JSON index.
2. Static vs. Dynamic Retrieval
- Static: Look up experience once at the start of a task using the task description.
- Dynamic: Refresh the "memory" at every step as the interaction history grows. (Interestingly, dynamic retrieval was found to be more unstable due to "context churn").
3. ExpRAG-LoRA (The Core Contribution)
The breakthrough comes from retrieval-augmented fine-tuning. During training, for every task in the training set, the system retrieves relevant trajectories and includes them in the prompt. The model is then supervised to produce the correct action conditioned on both the current history and the retrieved memory.
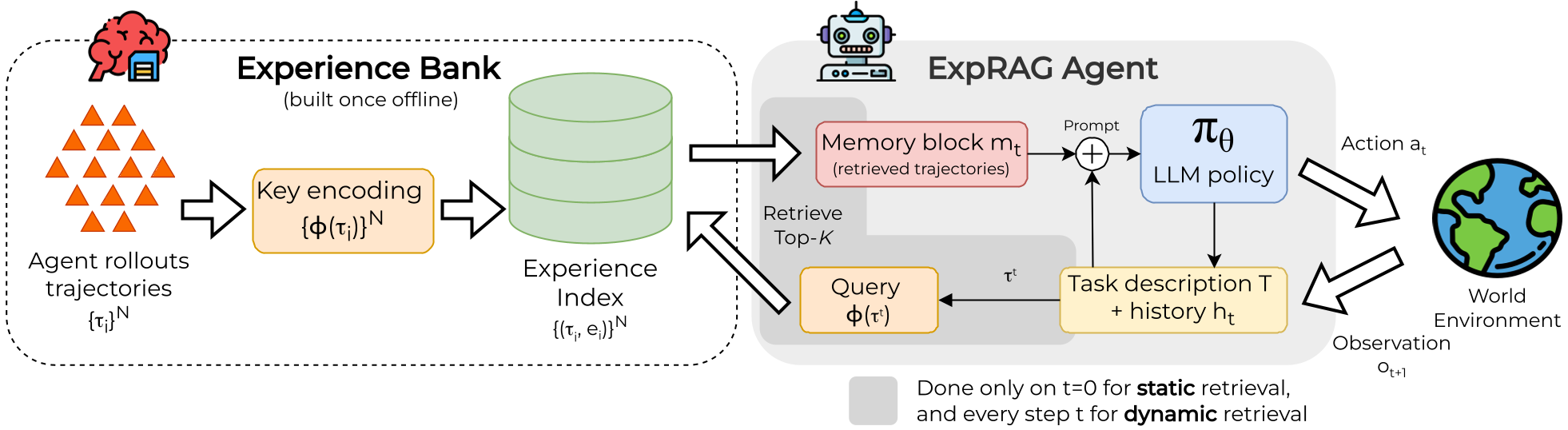 Figure 1: Overview of the ExpRAG agent loop—from experience bank construction to inference-time retrieval.
Figure 1: Overview of the ExpRAG agent loop—from experience bank construction to inference-time retrieval.
Experimental Battleground: ALFWorld & ScienceWorld
The authors tested their approach against heavyweight baselines.
- ALFWorld: Household tasks (e.g., "put a cool apple in the fridge").
- ScienceWorld: Elementary science experiments requiring complex reasoning.
Key Breakthrough: Delayed Generalization
A fascinating insight from the paper is that agents need to "overfit" to generalize. They found that even after validation loss starts to rise (usually a sign to stop training), the actual success rate on unseen tasks continues to climb. This "delayed generalization" suggests that the model undergoes a structural shift in how it processes context late in the training cycle.
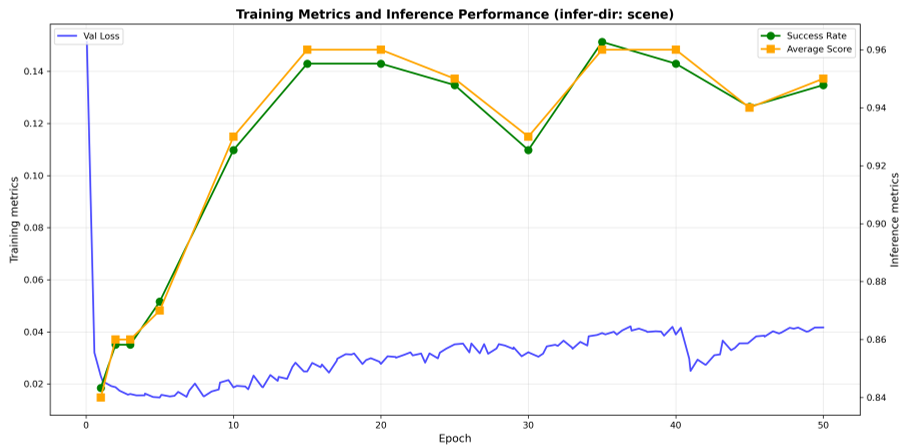 Figure 2: Despite rising validation loss (blue), the OOD success rate (green) often peaks much later, around epoch 50.
Figure 2: Despite rising validation loss (blue), the OOD success rate (green) often peaks much later, around epoch 50.
Results & Performance
The results are clear: ExpRAG-LoRA is the only method that maintains high performance across the board.
| Method | ALFWorld (Easy/In-Dist) | ALFWorld (Hard/OOD) | | :--- | :---: | :---: | | Zero-shot | 8.2% | 0.0% | | Standard LoRA | 98.6% | 34.4% | | ExpRAG-LoRA | 97.3% | 88.5% |
On ScienceWorld Hard tasks, ExpRAG-LoRA outperformed standard LoRA by 270% (42.2% vs 15.6% success).
Deep Insight: Why does it work?
By training with retrieval, the model develops an Inductive Bias toward using the provided context. When it encounters an "Out-of-Distribution" (OOD) task, standard models try to "hallucinate" an action based on training memory. ExpRAG-LoRA models, however, have been trained to look at the "Memory Block" first to find the strategy, allowing them to adapt to new rules on the fly.
Critical Analysis & Future Outlook
Limitations: The paper relies on "expert" trajectories for the memory bank. In a real-world setting, memory would be "self-generated" and noisy.
Takeaway: This work establishes a new "Gold Standard" baseline. Before building complex "Self-Reflecting" or "Cognitive Architectures," researchers should first ensure they are effectively using episodic retrieval during the training phase. The future of agents isn't just bigger models, but models that are better at "reading their own diaries."
Conclusion
ExpRAG-LoRA proves that episodic memory isn't just a "plugin" for inference—it's a training signal. By teaching models how to handle past experiences, we move closer to agents that can truly navigate the unknown.