The paper introduces a subgoal-driven framework for long-horizon LLM agents, featuring Gemini-SGO for online planning and MiRA (Milestoning your Reinforcement Learning Enhanced Agent) for offline training. The system addresses planning failures in complex web navigation, achieving a 43.0% success rate on WebArena-Lite with a Gemma3-12B backbone, significantly outperforming GPT-4o and previous open-source SOTA.
TL;DR
Web navigation is the "stress test" for AI agents, requiring dozens of steps where a single mistake leads to a loop. Google DeepMind researchers have tackled this with a two-pronged strategy: Gemini-SGO for real-time introspective planning and MiRA, a Reinforcement Learning (RL) framework that replaces sparse "win/loss" rewards with dense, milestone-based signals. The result? A 12B open model (Gemma3) that crushes GPT-4o's performance on web tasks.
Problem: The "Mid-Task Stuck" Phenomenon
Why do even the most powerful LLMs fail at booking a flight or managing a GitHub repo? Analysis shows that agents don't just "fail"; they get lost. In nearly 50% of failed trajectories, models like Gemini-2.5-Pro enter non-productive action loops—a "mid-task stuck" behavior.
The root causes are twofold:
- Online Execution: Agents lack situational awareness; they don't track which sub-parts of a task are finished.
- Training (RL): Rewards are typically binary (1 for success, 0 for failure). In a 50-step sequence, the agent has no idea which of the 49 intermediate actions were actually helpful.
Methodology: Milestoning the Agent's Journey
The authors propose a unified framework that treats subgoals as first-class citizens in both the agent's "thinking" and its "learning."
1. Dynamic Milestoning (Inference-Time)
Instead of blindly predicting the next click, the SGO (Subgoal-Oriented) framework forces the agent to ask three introspective questions at every step:
- What milestones have I achieved so far?
- Have I finished the current subgoal?
- What is the next future milestone?
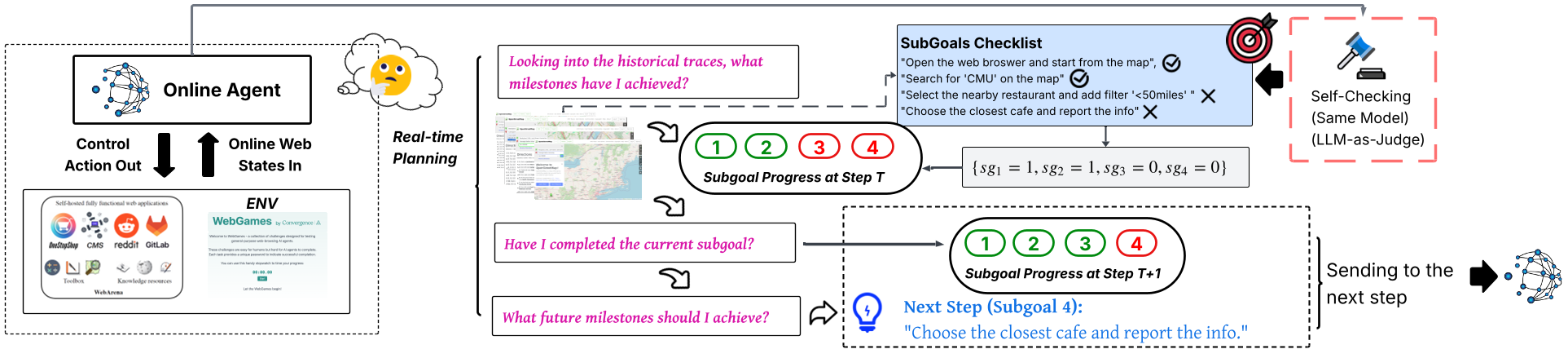 Figure: The real-time feedback loop where the agent's actions are monitored against a SubGoals Checklist.
Figure: The real-time feedback loop where the agent's actions are monitored against a SubGoals Checklist.
2. MiRA: Reward Shaping with a Potential Critic
To solve the credit assignment problem during RL, the authors introduce MiRA. It uses a Potential Critic () that learns to predict "progress" on a scale of 0 to 1. By interpolating between completed subgoals (e.g., "Navigated to search" -> 0.25, "Found item" -> 0.5), the reward signal becomes dense. The agent receives a "shaping reward" whenever it increases its potential—moving it closer to the next milestone even before the final goal is reached.
Experiments: Performance Leap
The framework was tested on WebArena-Lite, a rigorous benchmark covering Shopping, Maps, Reddit, and GitLab.
| Model | Avg. Success Rate (SR) | | :--- | :--- | | GPT-4o | 13.9% | | Gemini-2.5-Pro | 23.0% | | Gemini-2.5-Pro + SGO (Ours) | 32.1% | | Gemma3-12B + MiRA (Ours) | 43.0% |
The 12B Gemma3 model, when trained with MiRA, achieved a staggering 43.0% SR, proving that targeted RL with dense rewards can help small models punch far above their weight class.
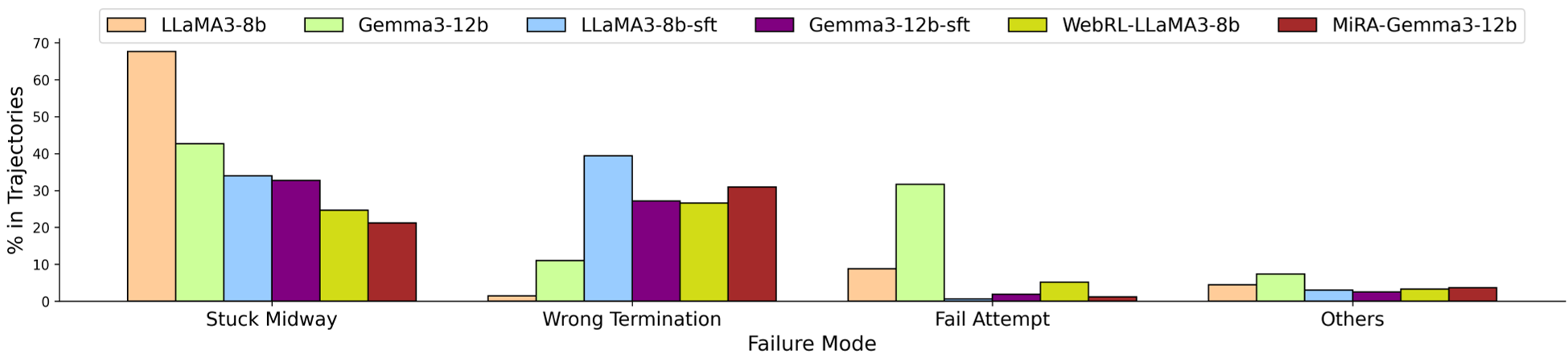 Figure: MiRA drastically reduces "Stuck Midway" errors (execution loops) compared to standard SFT and RL baselines.
Figure: MiRA drastically reduces "Stuck Midway" errors (execution loops) compared to standard SFT and RL baselines.
Deep Insight: Compiling Planning into Intuition
One of the most profound takeaways is the complementary nature of these two methods.
- MiRA (Training) essentially "compiles" complex navigation patterns into the model's weights. The agent develops an "intuition" for the right path.
- SGO (Inference) acts as a runtime guardrail, catching the model when its intuition fails in novel or dynamic scenarios.
The authors also noted a "behavioral phase transition" (Figure 12 in the paper). Early in training, agents stall at the first milestone. By the final phase of MiRA, completion probability follows a perfect diagonal gradient across time—indicating that the agent has learned to chain subgoals sequentially and efficiently.
Conclusion & Future Horizons
This work demonstrates that the bottleneck for LLM agents isn't just raw "intelligence" or parameter count—it's structured planning fidelity. By grounding the agent in semantically verifiable milestones, we move away from "hallucinated progress" toward robust digital coworkers.
The next frontier? Self-evolving autonomy, where the agent autonomously diagnoses its own failures to generate the very subgoals and curriculum needed for its next upgrade.